As we look back on the six-month grant funding Hanzo received from Innovate UK’s Sustainable Innovation Fund, we’re excited by the progress we’ve made and the new paths we have before us. If you missed my earlier posts, the fund was created to help companies recover from the disruption caused by the COVID-19 pandemic. We applied for a grant to work on building artificial intelligence models that could detect misbehaviour in Slack and other collaboration apps.
What does Slack have to do with COVID-19? The abrupt transition to remote work forced employees to find new ways to communicate with their teams, often through applications like Slack. But that wholesale migration of communications meant unknown workplace risks and new challenges in detecting and mitigating those risks. We’re looking for ways to use technology to sift through the thousands of daily messages that companies generate and identify potentially harmful content such as bullying and discrimination, as well as privacy risks such as data leakage.
While I’m planning to keep blogging about our continued progress on this work, the end of the grant seemed like an excellent opportunity to revisit why we believe this work is essential, look back at what we’ve done, and ponder where we’ll go from here.
The Need to Monitor Communications on Collaboration Apps Like Slack
We’re big fans of Slack here at Hanzo—but we’re also big believers in the critical importance of integrating any messaging platform used for business into the company’s information governance pipelines. That means preserving and collecting relevant data for ediscovery, deleting outdated and useless information, and identifying personal data in response to privacy-related requests.
Ideally, organisations would also ensure that employee communications on those platforms comply with the business’s standards for respect, professional behaviour, and non-discrimination. But therein lies the challenge: users on these platforms generate thousands of messages every day. There’s no way for any human to keep up with all of the chatter within and between teams. That creates the risk that bullying, discrimination, or other misbehaviour could be occurring right under supervisors’ noses—and unlike in the office, there won’t be anyone there to overhear or intervene. In a similar vein, private personal data could be leaked on these channels, whether maliciously or inadvertently, without detection.
That’s why we set out to build artificial intelligence models that could detect various risky behaviours in text-based communications. One important caveat: these tools are not intended to decide what behaviour is or isn’t acceptable. They are meant only to identify potential areas of concern so that those conversations can be referred to a human team for further review.
Recapping the Innovate UK Project
Our work under the grant followed two major themes: detecting abusive behaviour and identifying data leakage. We’ve had great success in building these models, thanks to publicly available datasets, such as the Amazon Mechanical Turk or MTurk forums, that we can use to teach our artificial intelligence systems what to look for. While it’s easy enough to detect specific words or variants denoting profanity, it’s considerably harder to detect patterns in language that indicate bullying, abuse, or discrimination. It’s always a subjective interpretation as to whether any message—or, more often, any cluster of messages—is problematic.
We saw this firsthand when we crowdsourced groups of nine people at a time to annotate thousands of messages. We set a simple majority threshold: if five or more people agreed that a message’s content was abusive or bullying, we tagged that message as bullying. Working as we were with enriched natural datasets rather than artificially manufactured teaching sets, we didn’t have many egregious examples of bullying behaviour. However, because we chose messages from threads that scored higher than average on a profanity model, we didn’t have that many “neutral” or non-abusive messages either. There was only a small set—about 10 percent of the total—that all nine of our reviewers agreed did not contain bullying, racism, or sexism. To ensure that our reviewers were giving us good feedback, we’ve also worked with a psychologist to develop and test these models.
Building a model to detect data leakage was quite a bit easier, thankfully. Moreover, that model only needed to learn to recognise parts of speech that might indicate names or locations and patterns in numbers—comparatively easy stuff!
What Comes Next for Our Artificial Intelligence Models?
As excited as I was to have the opportunity to start this project, I’m intrigued to see where we’ll go after it concludes. During the project, our scope was limited by the terms of the grant and our initial application. Now that we’ve wrapped up, we can expand the scope to follow some of the rabbit trails that we’d left unexplored.
One of my primary interests is in what we can learn from aggregation. I mean that in two different ways: aggregating data from different messages over time to spot trends or patterns in behaviour, and aggregating other models to obtain more accurate results. What we’re looking for are sustained deviations in behaviour, as you can see on some of our calendar heatmaps.
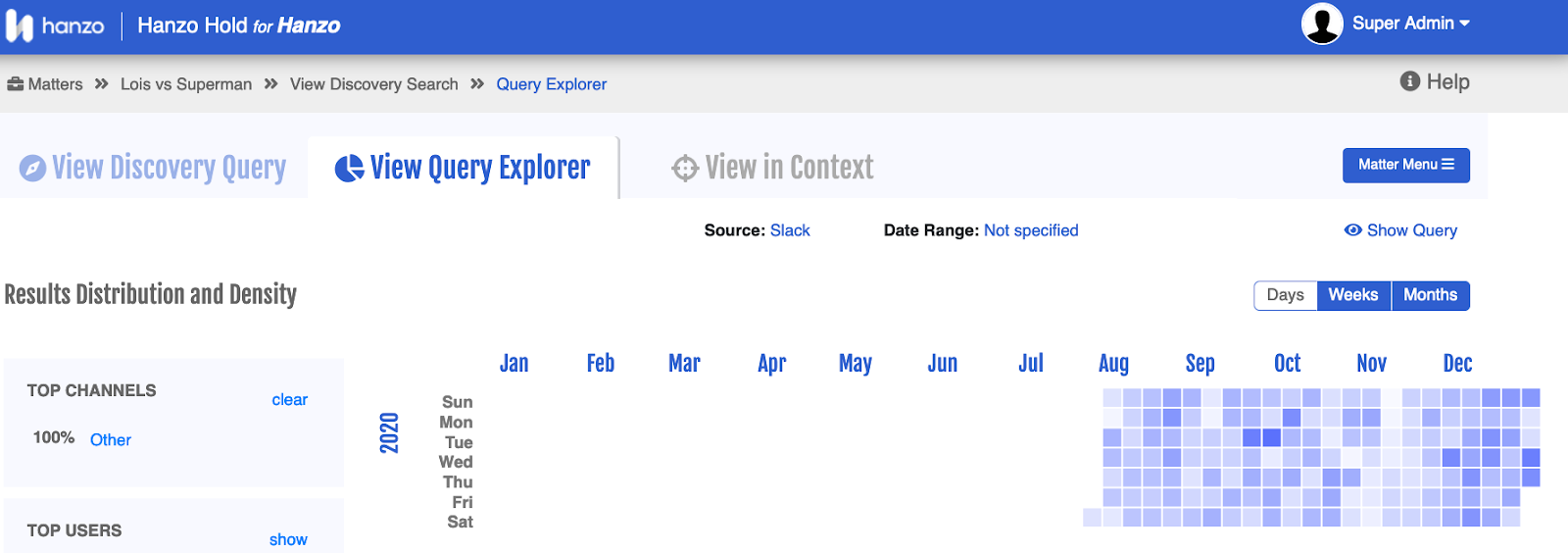
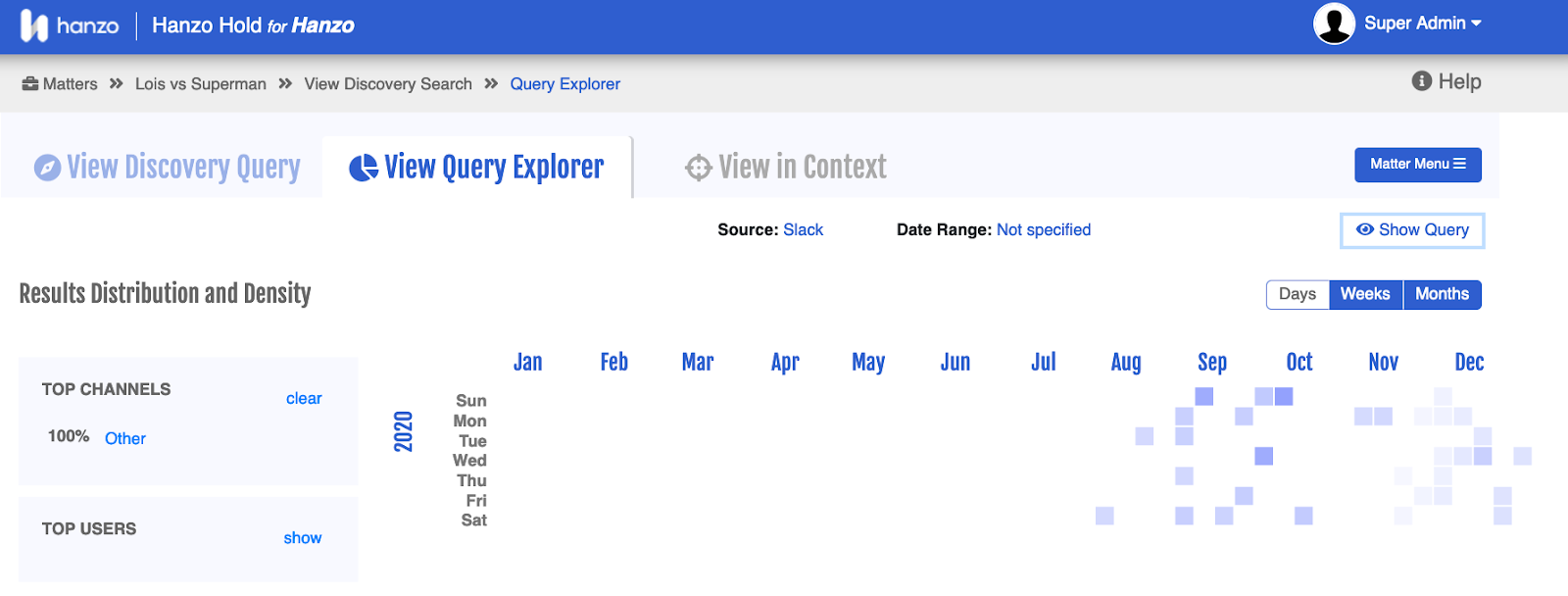
We’re also exploring what happens as we change the model’s thresholds for triggering human review. For example, a user could set a lower threshold for profanity on a customer-facing channel than on an internal-only channel.

In another vein, how many false positives or false negatives can the model tolerate before its utility declines? I’m looking forward to broadening the questions we ask of these models as we continue this work after the expiration of the grant funding.
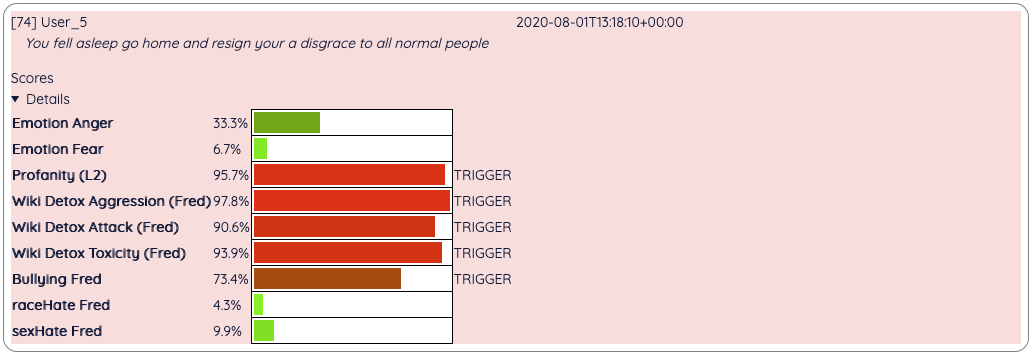
Example for a single safe for work message. (Note that we give models “friendly” names like Fred to make it easier to refer to them):
The challenge is protecting your workforce no matter where they are—and that’s what I hope these models will eventually help companies do.
[View source.]
