These days, data is a lot like physical possessions: you need at least some to function. Beyond that minimum, there’s a bigger universe that’s generally seen as useful. Up to a point, more is better, with each new piece opening the door to more possibilities.
Eventually, though, both data and possessions can exceed the capacity of their organizational systems. They start to pile up, becoming a burden rather than a boon. People end up in houses that barely function as homes because they’re overflowing with possessions that are too crowded and disorganized to offer any value.
This is where many modern enterprises find themselves with data.
The business world spent years singing data’s praises, extolling its ability to fuel strategic decision-making, operational efficiency, and customer engagement. Organizations had the power to answer any question if only they could gather and leverage the right data. From customer preferences and buying behaviors to production processes and supply chain logistics, data was a compass guiding businesses through uncharted territories.
But the data landscape is no longer a neatly organized repository. Data has rapidly expanded and evolved into a dynamic ecosystem characterized by complexity, variety, and sheer overwhelming volume. This intricate ecosystem, comprising both structured and unstructured data, presents opportunities that can revolutionize the way organizations operate and innovate — if they can find a way to manage it.

Businesses now face a pressing challenge in litigation matters: containing the rising costs associated with identifying, preserving, collecting, reviewing, and producing this deluge of information for eDiscovery. To address this challenge head-on, proactive information governance is essential.
So, how are businesses responding? That’s what Ari Kaplan sought to answer in his annual research project. He engaged 30 eDiscovery professionals — from in-house attorneys and legal professionals to law firm partners and litigation support leaders — to explore market trends, the impact of technology on efficiency, the growing role of artificial intelligence in the legal sector, and the continually changing challenges they face in managing data for information governance and eDiscovery.
The rising importance of information governance
The exponential growth of business data has inflated costs across every stage of the eDiscovery process. Identifying relevant data is harder than finding a needle in a haystack, while collecting and preserving data defensibly is not only resource-intensive but also fraught with potential pitfalls.
The review process — once overwhelming because it was a strictly manual task — is now overwhelming because legal teams are alternately unable to find relevant data or are drowning in a sea of data that must be carefully scrutinized.
Where is all that data lurking? Many organizations report a surge of data from shadow IT — unapproved software, including Zoom, Microsoft Teams, Slack, and other messaging and collaboration tools — as well as data hidden in private conversations and in SharePoint. Finding, collecting, and producing this data in a litigation-ready format demands meticulous attention to detail in addition to complex and costly procedures.
On a scale where 10 represents the highest degree of difficulty, the vast majority of law firm interviewees (79%) rated managing data in collaborative tools as a 7 or higher; most in-house respondents (69%) rated it as an 8 or higher. Both audiences agreed that integrating data from various sources into their current eDiscovery workflows was incredibly difficult and that their overall approach to data management hampered the efficiency and effectiveness of their eDiscovery processes.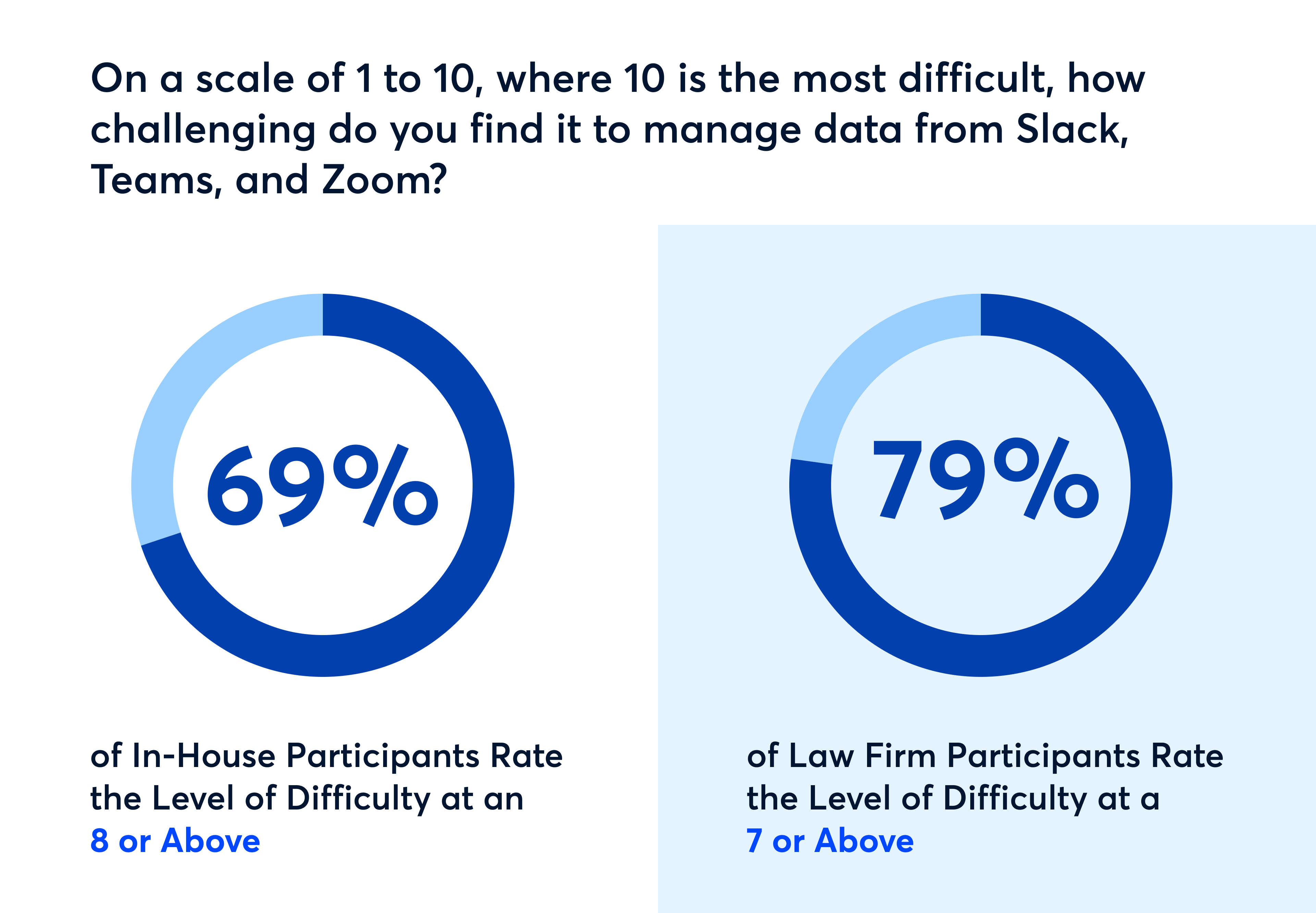
Information governance strategies that span the entire data lifecycle offer a beacon of hope. Instead of reacting haphazardly to data-related issues as they occur, organizations with robust information governance programs manage data from creation to disposal, significantly reducing the costs associated with eDiscovery at every stage of the process:
- Identification: By classifying and categorizing data at the point of creation, organizations can easily locate and retrieve relevant information when litigation arises. This saves time and eliminates the need for extensive data collection.
- Preservation: Effective information governance preserves information in a legally defensible manner, ensuring that data remains intact and reducing the risk of spoliation.
- Collection: When legal teams need to collect data for a case, data mapping expedites the process of locating data sources and custodians; data maps outline where data resides, who has access to it, and how it’s used. Clear retention guidelines also reduce the volume of data subject to collection.
- Review: By implementing data retention policies and disposal schedules, organizations can minimize the volume of data for review. Advanced analytics and machine learning technologies, integrated within the governance framework, further enhance review efficiency by pinpointing relevant information with greater accuracy.
- Production: With well-defined data management policies, organizations can produce data rapidly, reducing the time and resources required for formatting and validation.
But the traditional approaches that many organizations still use for data management are insufficient today. They lack the scalability, efficiency, and flexibility required to handle today’s vast data volumes and complexities necessary for sound information governance and eDiscovery. Departmental data silos, piecemeal collection efforts, and manual review processes aren’t enough to meet the need for real-time insights and collaboration.
Fortunately, there's a better way.
The benefits of a cross-functional approach to data management
Today’s advanced software platforms fueled by artificial intelligence take a cross-functional approach to data management, enhancing information governance and streamlining eDiscovery. These software solutions are designed to break down departmental silos and accelerate access to key data for legal and compliance matters.
Here’s how organizations can benefit from these solutions:
A centralized repository where data from various departments is stored, indexed, and organized. This repository, which connects to different platforms to collect data through an API, serves as a single source of truth for all data-related activities, simplifying the implementation of consistent data management policies and legal holds. Readily accessible data also reduces the time and effort, and thus expense, required to identify and collect relevant information. In a cross-departmental approach, the likelihood of redundant data collection, storage, and management efforts is low. Duplicate data entry, multiple storage locations, and inconsistent practices are minimized, leading to efficient resource utilization and cost savings.
Better enforcement of data classification and retention policies. A unified approach ensures that data is categorized, tagged, and retained according to established guidelines. It becomes easier to track data flows, demonstrate compliance with data protection and retention regulations, and identify and preserve relevant data, improving defensibility. A collaborative approach also facilitates consistent data retention and disposal policies. Organizations can avoid the expenses of maintaining and preserving obsolete or irrelevant data and reduce the risk of spoliation.
Stronger collaboration between departments and teams. Robust data management platforms enable cross-departmental workflows, approvals, and communication, ensuring that legal, compliance, IT, and other stakeholders work together seamlessly. Collaborative workflows accelerate responses to litigation requests, reducing delays and minimizing the risk of noncompliance.
A strong foundation for generative AI efforts. Part of preparing an organization's proprietary data for use in generative AI involves understanding what resides within unstructured data and identifying which data is relevant. Getting a hold of data management and consolidating data from legacy systems provide opportunities to undertake this exercise.
Deeper insights into data usage, access patterns, and compliance status. These insights allow organizations to monitor and assess the effectiveness of data management policies and allow legal teams to pinpoint relevant data sources, apply data-culling strategies, and develop case strategies.
More accurate data culling during eDiscovery. Reducing the volume of data subject to review translates into lower legal review costs. Advanced analytics and machine learning technologies can further pinpoint relevant data, optimizing the review process.
Lower risk of exposing proprietary information. Cross-functional software can enhance data security and reduce the likelihood of sensitive information falling into the wrong hands. This software categorizes and labels proprietary information, making it easier to identify and protect sensitive data. It can also set up granular access controls and permissions for data based on user roles and responsibilities, along with secure file sharing and data encryption. This ensures that only authorized personnel have access to proprietary information, minimizing the risk of improper sharing.
In short, a cross-functional approach to data management ensures that the entire organization is aligned in safeguarding proprietary information. The right tools and a cross-departmental approach increase efficiency, reduce risk, and lower cost while promoting data security, improving compliance, and fostering a corporate culture of responsible data management.
